Answer 1
(a). Arrange the data of 20 student’s result
| Student number | Results |
| 1 | 42 |
| 2 | 53 |
| 3 | 54 |
| 4 | 61 |
| 5 | 61 |
| 6 | 61 |
| 7 | 62 |
| 8 | 63 |
| 9 | 64 |
| 10 | 66 |
| 11 | 67 |
| 12 | 67 |
| 13 | 68 |
| 14 | 69 |
| 15 | 71 |
| 16 | 71 |
| 17 | 76 |
| 18 | 78 |
| 19 | 81 |
| 20 | 83 |
| Total | 1318 |
Data has arranged in ascending order for getting correct results.
- Compute Mean, Median and Mode
To calculate mean , following formula will implement:
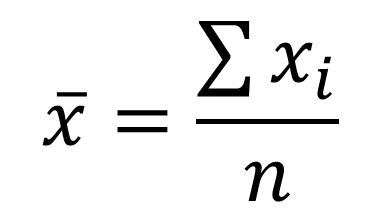
Σ xi /9Total of marks) =1318; n (number of students)=20
131820= 65.9 is the mean value of student’s results.
Median calculation
Median = N2+1=202+1=11th Item of the above table will be median
Median is 67
- Compute 1st and 3rd Quartile
1st Quartile = 14 N+1 = 20+1/4 = 5th Item = 61
3rd Quartile =34N+1=3420+1=634=15th item=71
- Compute and Intercept 90th Percentile
Formula = 90% of total number of students(observation) = 0.90*20 = 18th Item = 78
(b) Inferential Statistics:
Inferential statistics include select sample from the available observation, in order to identify or solve the issue through applying appropriate tests. These tests are also helpful in hypothesis testing and prove the outcome with valid numbers.
Answer 2
(i) Prepare Joint Probability Table
| Applied for More than 1 University | ||||
| Age Group | Yes | No | ||
| 23 and Under | 207 | 207/808*100=25.62% | 201 | 201/1210*100=16.61% |
| 24-26 | 299 | 299/808*100=37.0% | 379 | 379/1210*100=31.32% |
| 27-30 | 185 | 185/808*100 = 22.90% | 268 | 268/1210*100=22.15% |
| 31-35 | 66 | 66/808*100=8.17% | 193 | 193/1210*100= 15.95% |
| 36 and over | 51 | 51/808*100=6.31% | 169 | 169/1210*100= 13.97% |
| Total / Joint Probability(%) | 808 | 100% | 1210 | 100% |
(ii) Given that a student applied to more than 1 university, what is the probability that the student is 24-26 years old.
Probability of student is 24-26 years old = 299/808 =37.00%
- Is the number of universities applied to independent of student age? Explain
Student age is an independent variable against number of observation collected for application made for enrolment in more than one university at a time. Any student at any age can take enrolment of in more than one university or they can adopt only one university at a time.
(b)
Information provided-
| x | f(x) |
| 10 | 0.05 |
| 20 | 0.1 |
| 30 | 0.1 |
| 40 | 0.2 |
| 50 | 0.35 |
| 60 | 0.2 |
| Total |
X represent number of new clients for counselling cases in the year 2021.
Formula of calculating Expected value = ?(?) = ? = ∑? ∗ ?(?)
| x | f(x) | (? − ?) 2 | (? − ?) 2*f(x) | |
| 10 | 0.05 | -33 | 1089 | 54.45 |
| 20 | 0.1 | -23 | 529 | 52.9 |
| 30 | 0.1 | -13 | 169 | 16.9 |
| 40 | 0.2 | -3 | 9 | 1.8 |
| 50 | 0.35 | 7 | 49 | 17.15 |
| 60 | 0.2 | 17 | 289 | 57.8 |
| Total | 201 |
Expected Value= (10*0.05+20*0.1+30*0.1+40*0.2+50*0.35+60*0.2) =43
Formula of Variance of a discrete random variable ???(?) = ∑(? − ?) 2 ?(?)
Variance = 201 (calculation shows in table)
Answer 3
- Formulate Hypothesis :
Problem statement: Population annual expenditure on prescription drugs per person is lower in the Midwest than the Northeast.
Hypothesis Statement:
Ho: µ ≤ $838 or
Ho: µ = $838
Ha: µ > $838
Problem statement can test on one tail test from left tail as it requires testing of lower limit.
- Suitable test Statistics
One (Left) tail test
Formula:

- Calculate value of relevant test statistics and P- value
Sample Mean (x) = $745
Null Hypothesis Mean = $838
SD = 300
Sample size = 60
Applying Formula (745-838)/300/sqrt(n)
Z= -93/38.75 = -2.40
From the table given of Z score , at significance level of 0.05 ,
P value = 0.0071
- Based on the p value in part (III), at 99% confidence level, decide the decision criteria.
If the confidence level is 99% then there is 1% of significance level for this problem and at this level the critical value is 2.326 , for this Z-score is -2.4 which is less than critical value (2.326> -2.4). Null hypothesis shall be rejected.
- Make the conclusion Based on the analysis.
As per rejection of null hypothesis, it is concluded that the prescribed drugs expenditure is not lower in Midwest as comparison to Northwest.
Answer 4
- State the null and alternative hypothesis for single factor ANOVA to test for any significant difference in the mean price of gasoline for the three brands.
Hypothesis
H0 = µ1= µ2= µ3
H1 = µ1≠µ2≠ µ3
(ii) State the decision rule at 5% significance level.
Reject the H0 id t stat > Z critical value, Otherwise accept the null hypothesis
(iii) Calculate the test statistics
| A | B | C | |
| 3.77 | 3.83 | 3.78 | |
| 3.72 | 3.83 | 3.87 | |
| 3.87 | 3.85 | 3.89 | |
| 3.76 | 3.77 | 3.79 | |
| 3.83 | 3.84 | 3.87 | |
| 3.85 | 3.84 | 3.87 | |
| 3.93 | 4.04 | 3.99 | |
| 3.79 | 3.78 | 3.79 | |
| 3.78 | 3.84 | 3.79 | |
| 3.81 | 3.84 | 3.86 | |
| Sample Mean | 3.811 | 3.846 | 3.85 |
| Varience | 0.003349 | 0.004844 | 0.00382 |
ANOVA one- way test Formula
Formula F= MSTR / MSE
MSTR = ???? / ? – 1
MSE = SSE /?r – k
?Ӗ= (3.81 + 3.84 + 3.85)/3 = 3.83
SSTR= 10(3.81- 3.83)2 + 10(3.84-3.83)2 + 10(3.85-3.83)2 = 0.009
MSTR = 0.009/ (3-1) = 0.0045
P-value and critical value approaches
Value of test statistic
SSE = 9(0.003) +9(0.005) + 9(0.004) =0.108
MSE = 0.108/(30-3) = 0.004
F= 0.0045/0.004 =1.125
ANOVA Table
| Source of variation | Sum of Squares | Degrees of Freedom | Mean Square | F | P- value |
| Treatment | 0.009 | 2 | 0.0045 | 1.125 | 0.044 |
| Error | 0.108 | 27 | 0.004 | ||
| Total | 0.117 | 29 | 0.0085 |
P- value calculation
Here Numerator df = 2; Denominator Df = 27 then the value of F at 0.01 = 5.49
Decision on the basis of test
The p-value < .05, So null hypothesis shall be rejected
Decision as per critical value approach
Based on an F distribution with 2 numerator d.f. and 27 denominator d.f., F.05 = 3.35.
Reject H0 if F < 3.35
Here F = 1.125 <3.35 which is evidence for rejection of null hypothesis.
(d) Based on the calculated test statistics decide whether any significant difference in the mean price of gasoline for three bands.
The value of F is 1.125 which is lower than F critical value this means hypothesis has been rejected that means there is significant difference in the mean price of gasoline in all the three brands.
Answer 5
- Complete the missing entries from A to H in this output
A= R Square = SSR/SST = 35250755.68/ 42699148.82 = 0.82
B= Observation = 50 (provided in Answer)
C= residual = Total- Regression = 49-2 = 47
D= 42699148.82-7448393.14 = 35250755.68
E= SSRegression / dfreg. = 35250755.68/2 = 17625377.8
F= SSR /(50-3) = 7448393.148/47 = 158476.45
G= 17625377.8/158476.45 = 111.217647
H= Coefficient of income /Standard error of income = 8.36
- Estimate the annual credit card charges for a three-person household with an annual income of $40,000
To estimate charges of credit card , intercept, household value and size has been considered from the ANOVA table.
The annual credit card charges for three person family is $3700 where annual income is $40000.
- Did the estimated regression equation provide a good fit to the data? Explain
No, The reason behind the same is high variability between two variables X and Y which fails in establishing good fit to the data.
Answer 6
- Using linear trend equation forecast the sales of face masks for October 2020
| Month | Sales ($) |
| 1 | 17000 |
| 2 | 18000 |
| 3 | 19500 |
| 4 | 22000 |
| 5 | 21000 |
| 6 | 23000 |
Linear Trend Equation = Y= Mx+B
M= Y2-Y1X1-X2 = 23000-21000/6-5 = 2000/1 = 2000
Y = Mx+B
Y= ?
X=1
B= 23000
Y = 2000*1+23000
Y = 2000+23000= 25000
$25000 will be the forecasted sale in the month of October.
- Sales forecast will be
| Sales | Weight | Weighted Sale | |
| July | 22,000 | 0.2 | 4400 |
| August | 21,000 | 0.3 | 6300 |
| September | 23,000 | 0.5 | 11500 |
| Total | 22200 |
So, the expected sale for the next month will be $22200